

Seedance 2.5 is not a generalist model that does everything at an average level. Its specific upgrades, 30-second native generation, 50 reference inputs, improved prompt accuracy, region editing, and native audio sync, make it particularly well suited to certain kinds of work.
Here are the use cases where it earns its place.
Brand Films and Product Ads
A proper 30-second ad has three parts: an opening shot to establish the product, a middle section to demonstrate it, and a closing frame with the call to action. With most AI video models, that means generating three separate clips and stitching them together, then hoping the product looks consistent across the joins.
Seedance 2.5 generates the full 30 seconds in one pass. Your product looks the same in the opening wide as it does in the final close-up, because it is all one generation. Add a product image as a reference, a brand video clip for style direction, and an audio file for the sound, and you have a complete brief loaded before you even write the prompt.
For teams producing multiple campaign variants daily, the 20% improvement in prompt adherence means fewer generations before you get something usable. Region editing handles the rest: if one specific element is off, you fix only that part without re-rolling the whole clip.
Multi-Character Scenes and Short Films
Most AI video models struggle with more than one character in a frame. Appearances drift between shots. Faces change. The second character looks like a different person by the third generation.
Seedance 2.5's 50-reference system changes this. Upload a reference image for each character and the model anchors to them throughout the full clip. At the launch demo, ByteDance ran more than ten actor references in a single generation and held each character's appearance stable across the scene.
For filmmakers and anyone making narrative content, this opens up multi-person scenes that were not reliably possible before. You can cast your video from a folder of reference images rather than hoping the model invents consistent-looking people across 30 seconds.
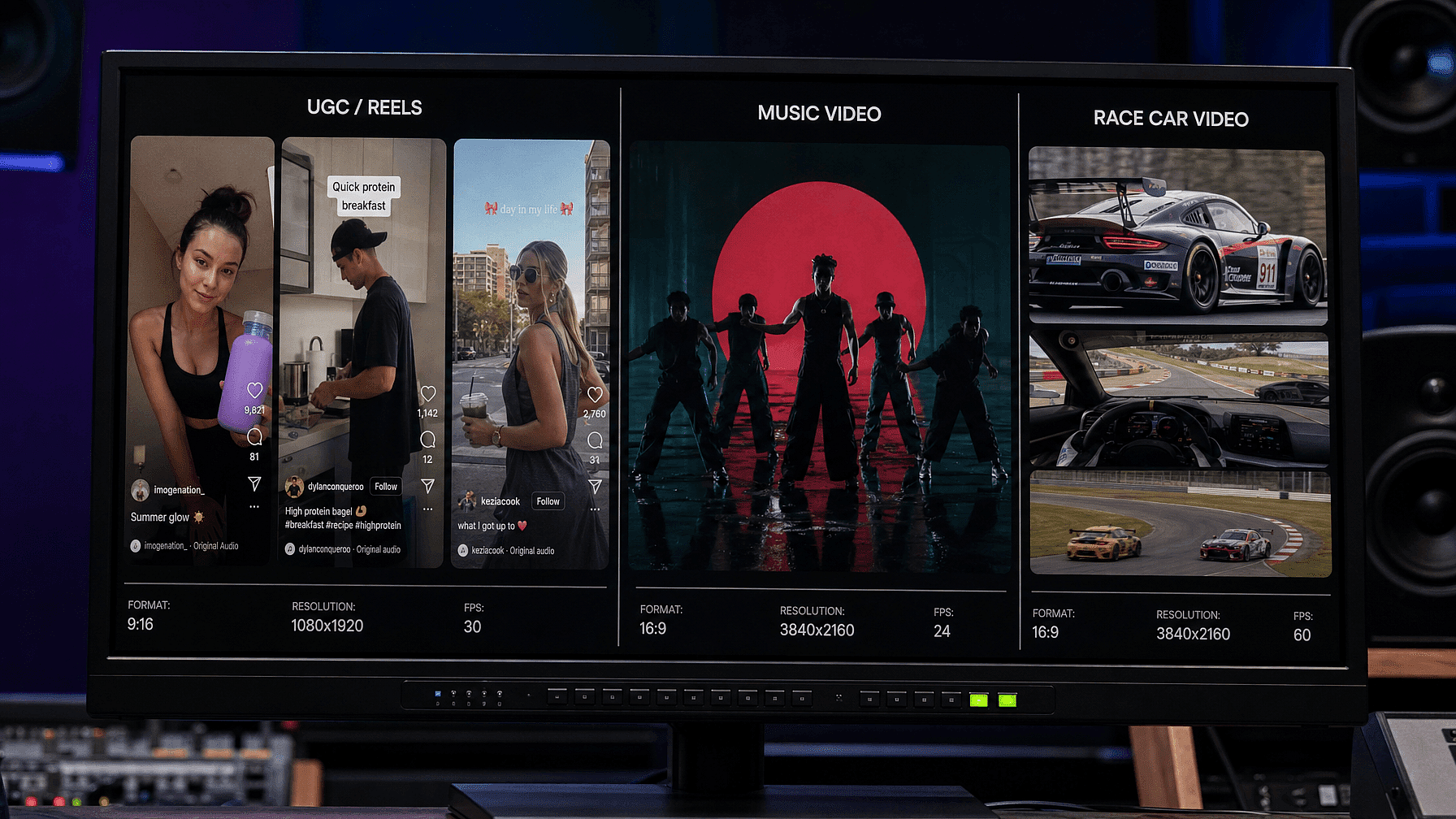
Social Content and UGC at Scale
Content teams that publish daily live by iteration speed. The question is not just whether the output is good, it is how many generations it takes to get there.
Seedance 2.5 helps on both sides of that. The improved prompt adherence means your first generation is more likely to be close to what you asked for. And when something specific is wrong, region editing lets you fix only that element without regenerating the whole clip.
For a team producing 20 or 30 video variants a week, those savings per generation add up. Fewer credits spent on re-rolls, faster turnaround per asset, and more time on the creative decisions that actually matter.
3D Product and Architectural Visualisation
This is where Seedance 2.5 does something no other consumer AI video model offers.
Supply an untextured 3D mesh of a product, a room, or a structure, and Seedance 2.5 uses it to lock in the camera position, proportions, and spatial layout before generating the final output. The result follows the 3D blockout precisely, which gives you frame-level compositional control over the shot.
For product designers, architects, and VFX teams, this makes Seedance 2.5 a previsualization tool as much as a video generator. Rough out the composition in 3D, generate the full textured render from it, and use region editing to clean up specific elements afterward. It collapses a workflow that used to require separate software into a single generation step.
Music Videos and Cinematic Content
Seedance 2.5 generates audio in the same pass as the video. The sound is not synced after the fact, it is produced alongside the visual in the same generation, which creates a natural relationship between what you see and what you hear.
For music video work, feed an audio reference of the track into your reference pool, describe the visual scene and camera movement, and the model generates a clip where the visuals feel like they belong with the sound rather than being laid over it.
Combined with 30-second native generation and the ability to describe a full camera arc in your prompt, this makes Seedance 2.5 well suited to long-form, sound-driven content where the visual and audio need to feel like a single piece, not two separate outputs assembled together.
All five of these use cases map to specific things Seedance 2.5 does differently from what came before. The 30-second pass, the reference system, the audio co-processing, the 3D input, these are not general improvements. They are targeted upgrades that each unlock a specific category of work.
Pick the one that matches your workflow and start there with OpenArt’s AI video generator!