SVD BatchandCaptions (EnglishorChinese)
5.0
0 reviews
Description
The purpose of this workflow is to address basic issues, with the possibility of expansion if needed. The problems to be solved are:
1. How to batch convert images into continuous SVD(SVD==StableVideoDiffusion) videos.
2. How to add captions to SVD videos (in Chinese or English).
3. How to batch add captions to regular images.
The workflow is entirely completed through ComfyUI, without the need for other software to add captions, and all image descriptions are generated by AI. The workflow is categorized into the following groups:
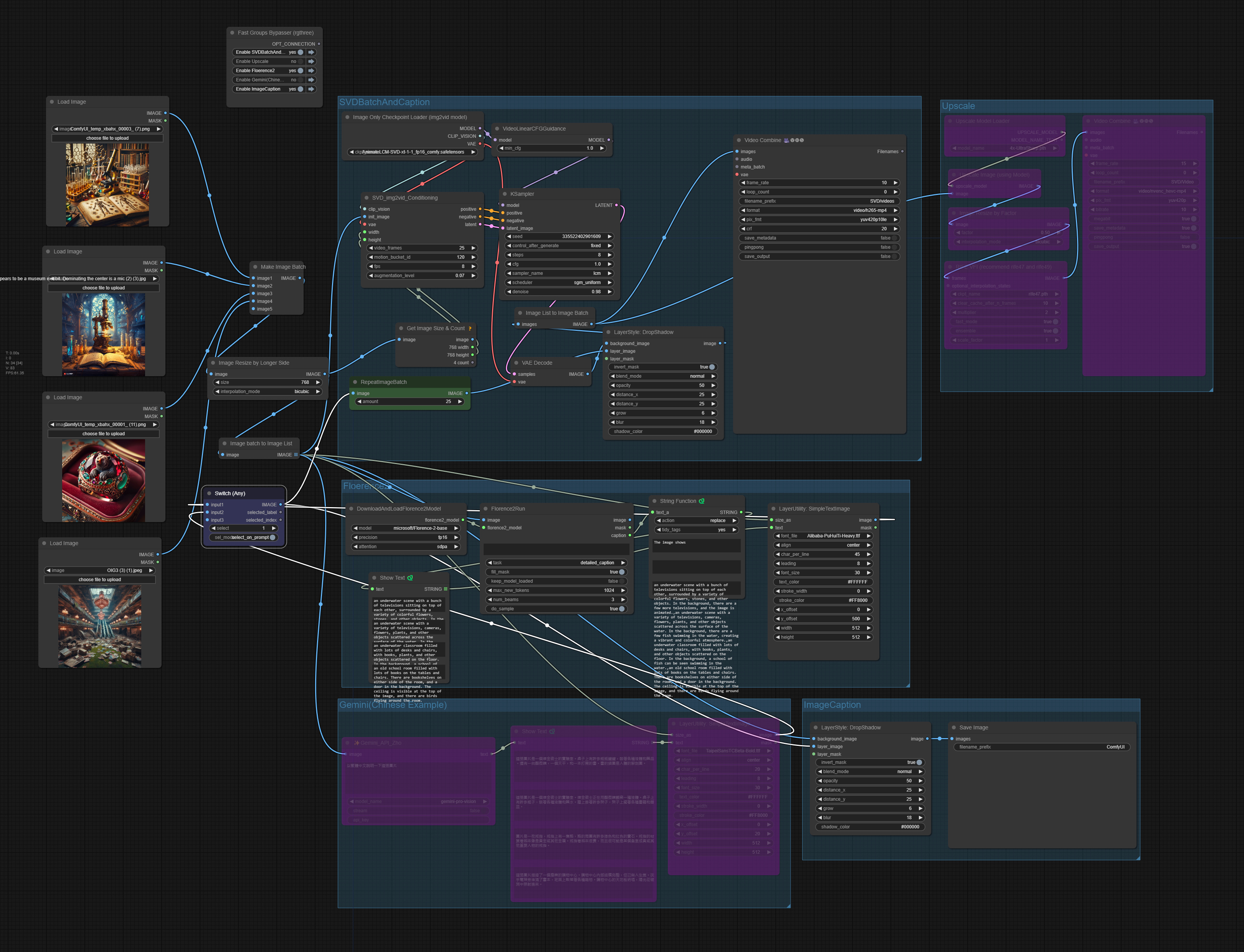
1. SVDBatchAndCaption: Converts input images into SVD videos and adds captions. Here, the LCM model is used. If the computer's computing power is sufficient or using cloud services, the general SVD-XT model can be used. The number of "RepeatImageBatch" must equal the SVD frames.
2. Florence2: Adds English captions and merges the subtitles into the SVD.
3. Gemini(ChineseExample): Adds Chinese captions and merges the subtitles into the SVD.
The caption position and size used in 2 and 3 are basically designed for 768*768. Adjust them according to the image or video size to avoid subtitles going off-screen.
4. ImageCaption: Batch adds captions to regular images. This group can be used to test before making videos. It can also be used to purely batch add AI-generated captions to images.
5. Upscale: Enhances the quality of SVD videos.
Switch: Switch 1 corresponds to the preset Florence2 group, and Switch 2 corresponds to the Gemini Chinese subtitle group. To use Chinese, select Switch 2 and Chinese subtitles. If using Simplified Chinese, modify the prompt accordingly.
Previously, I didn't know how to link SVD videos together, always making them one by one and then connecting them. Adding subtitles was also done separately. Now I understand the concept of batching a little bit, so I created this basic workflow to solve the problems.
==
工作流的目的是用以解决基本的问题,若有需要可以自行扩张。
要解决的问题是:
1、 如何批次把图片做成SVD的连续影片
2、 如何将SVD影片打上图片说明 (中文或英文)
3、 如何批次将一般图片打上说明
工作流完全透过ComfyUI完成,不需要其他软件上字幕,且图片说明均由AI产生,工作流的群组分类如下。
1、 SVDBatchAndCaption,将输入的图片转为SVD影片,并打上说明,此处使用LCM模型,若计算机算力足够或使用云端,可使用一般SVD-XT模型,「RepeatImageBatch」的数字,需等于SVD的Frames
2、 Florence2,打上英文标记,并把字幕合入SVD
3、 Gemini(ChineseExample),打上中文标记,并把字幕合入SVD
2与3所使用的标记位置及大小,基本为了768*768设计,可视图片或影片大小自己调整,以避免字幕跑出屏幕外。
4、 ImageCaption,将一般图片批次打上标记,出影片前可使用这群组测试,纯粹批次将图片打上AI字幕说明也可以使用。
5、 Upscale,提升SVD影片画质
Switch,开关,开关1是对应预设的Florence2群组,开关2是Gemini中文字幕群组,若要使用中文需选择开关2与中文字幕,若是简体中文,修改提示词即可。
以前都不知道如何串联SVD影片,总是一个个做好再接上去,想要字幕也另外合并,现在终于对批次概念有些了解,故做了本工作流来解决问题。
Discussion
(No comments yet)
Loading...
Reviews
No reviews yet
Versions (1)
- latest (2 years ago)
Node Details
Primitive Nodes (3)
DownloadAndLoadFlorence2Model (1)
Fast Groups Bypasser (rgthree) (1)
Florence2Run (1)
Custom Nodes (31)
ComfyUI
- ImageOnlyCheckpointLoader (1)
- RepeatImageBatch (1)
- SVD_img2vid_Conditioning (1)
- VideoLinearCFGGuidance (1)
- SaveImage (1)
- VAEDecode (1)
- ImageUpscaleWithModel (1)
- LoadImage (4)
- KSampler (1)
- RIFE VFI (1)
- ImpactImageBatchToImageList (1)
- ImageListToImageBatch (1)
- ImpactMakeImageBatch (1)
- ImpactSwitch (1)
- LayerStyle: DropShadow (2)
- LayerUtility: SimpleTextImage (2)
- Gemini_API_Zho (1)
- VHS_VideoCombine (2)
- GetImageSizeAndCount (1)
- StringFunction|pysssss (1)
- ShowText|pysssss (2)
- JWImageResizeByLongerSide (1)
- JWImageResizeByFactor (1)
- Upscale Model Loader (1)
Model Details
Checkpoints (1)
AnimateLCM-SVD-xt-1-1_fp16_comfy.safetensors
LoRAs (0)